Introduction
Each year, Etsy hosts an event known as “CodeMosaic” – an internal hackathon in which Etsy admin propose and build bold advances quickly in our technology across a number of different themes. People across Etsy source ideas, organize into teams, and then have 2-3 days to build innovative proofs-of-concept that might deliver big wins for Etsy’s buyers and sellers, or improve internal engineering systems and workflows.
Besides being a ton of fun, CodeMosaic is a time for engineers to pilot novel ideas. Our team’s project this year was extremely ambitious – we wanted to build a system for stateful machine learning (ML) model training and online machine learning. While our ML pipelines are no stranger to streaming data, we currently don’t have any models that learn in an online context – that is, that can have their weights updated in near-real time.
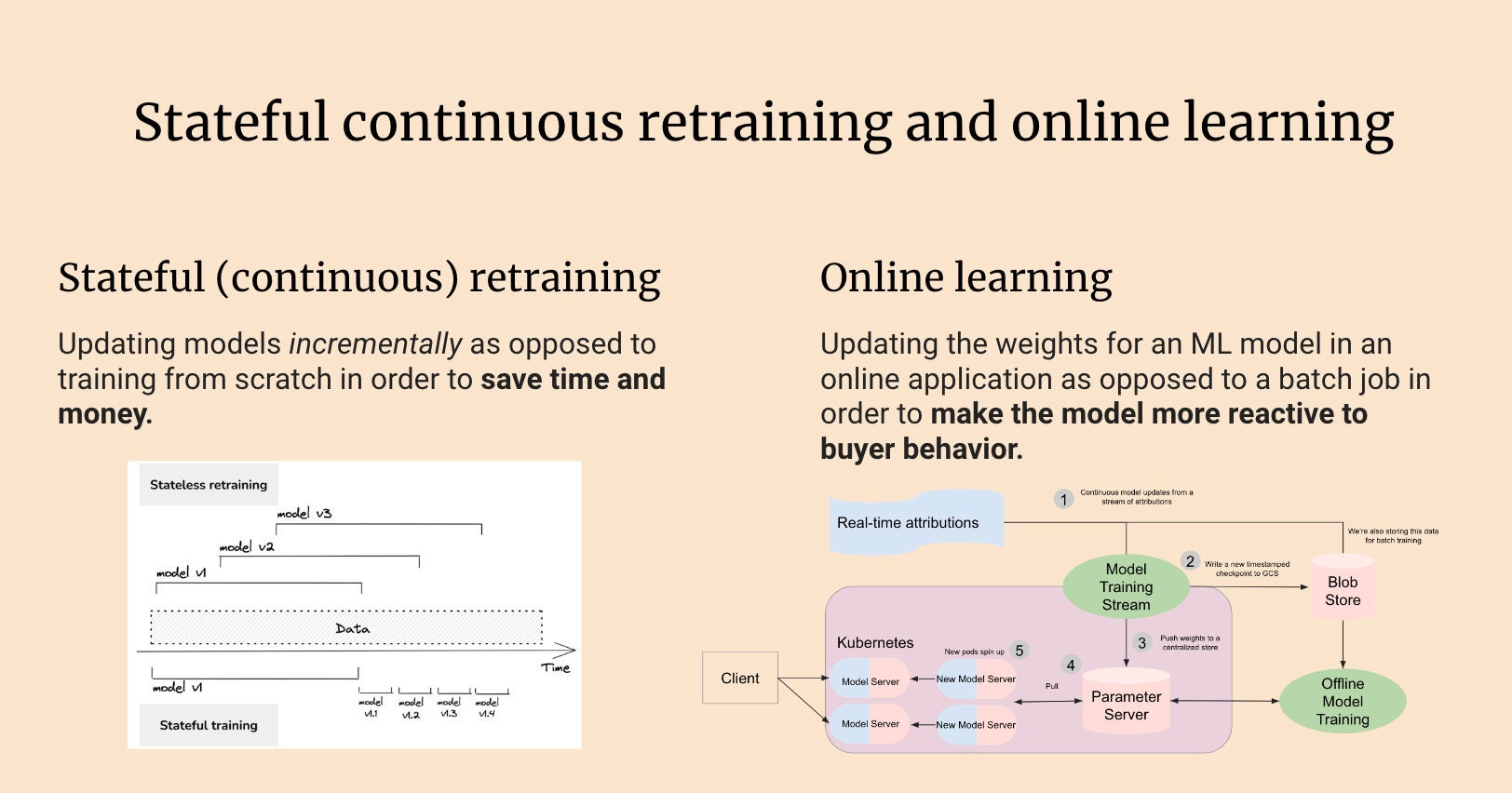
Stateful training updates an already-trained ML model artifact incrementally, sparing the cost of retraining models from scratch. Online learning updates model weights in production rather than via batch processes. Combined, the two approaches can be extremely powerful. A study conducted by Grubhub in 2021 reported that a shift to stateful online learning saw up to a 45x reduction in costs with a 20% increase in metrics, and I’m all about saving money to make money.
Day 1 – Planning
Of course, building such a complex system would be no easy task. The ML pipelines we use to generate training data from user actions require a number of offline, scheduled batch jobs. As a result it takes quite a while, 40 hours at a minimum, for user actions to be reflected in a model’s weights.
To make this project a success over the course of three days, we needed to scope our work tightly across three streams:
Real-time training data – the task here was to circumvent the batch jobs responsible for our current training data and get attributions (user actions) right from the source.
A service to consume the data stream and learn incrementally – today, we heavily leverage TensorFlow for model training. We needed to be able to load a model’s weights into memory, read data from a stream, update that model, and incrementally push it out to be served online.
Evaluation – we’d have to make a case for our approach by validating its performance benefits over our current batch processes.
No matter how much we limited the scope it wasn’t going to be easy, but we broke into three subteams reflecting each track of work and began moving towards implementation.
Day 2 – Implementation
The real-time training data team began by looking far upstream of the batch jobs that compute training data – at Etsy’s Beacon Main Kafka stream, which contains bot-filtered events. By using Kafka SQL and some real-time calls to our streaming feature platform, Rivulet, we figured we could put together a realistic approach to solving this part of the problem.
Of course, as with all hackathon ideas it was easier said than done. Much of our feature data uses the binary avro data format for serialization, and finding the proper schema for deserializing and joining this data was troublesome. The team spent most of the second day munging the data in an attempt to join all the proper sources across platforms. And though we weren’t able to write the output to a new topic, the team actually did manage to join multiple data sources in a way that generated real-time training data!
Meanwhile the team focusing on building the consumer service to actually learn from the model faced a different kind of challenge: decision making. What type of model were we going to use? Knowing we weren’t going to be able to use the actual training data stream yet – how would we mock it? Where and how often should we push new model artifacts out?
After significant discussion, we decided to try using an Ad Ranking model as we had an Ads ML engineer in our group and the Ads models take a long time to train – meaning we could squeeze a lot of benefit out of them by implementing continuous training. The engineers in the group began to structure code that pulled an older Ads model into memory and made incremental updates to the weights to satisfy the second requirement.
That meant that all we had left to handle was the most challenging task – evaluation. None of this architecture would mean anything if a model that was trained online performed worse than the model retrained daily in batch. Evaluating a model with more training training periods is also more difficult, as each period we’d need to run the model on some held-out data in order to get an accurate reading without data leakage.
Instead of performing an extremely laborious and time-intensive evaluation for continuous training like the one outlined above, we chose to have a bit more fun with it. After all, it was a hackathon! What if we made it a competition? Pick a single high-performing Etsy ad and see which surfaced it first, our continuously trained model or the boring old batch-trained one?
We figured if we could get a continuously trained model to recommend a high-performing ad sooner, we’d have done the job! So we set about searching for a high-performing Etsy ad and training data that would allow us to validate our work.
Of course, by the time we were even deciding on an appropriate advertised listing, it was the end of day two, and it was pretty clear the idea wasn’t going to play out before it was time for presentations. But still a fun thought, right?
Presentation takeaways and impact
Day 3 gives you a small window for tidying up work and slides, followed by team presentations. At this point, we loosely had these three things:
Training data from much earlier in our batch processing pipelines
A Kafka consumer that could almost update a TensorFlow model incrementally
A few click attributions and data for a specific listing
In the hackathon spirit, we phoned it in and pivoted towards focusing on the theoretical of what we’d been able to achieve!
The 1st important potential area of impact was cost savings. We estimated that removing the daily “cold-start” training and replacing it with continuous training would save about $212K annually in Google Cloud costs for the 4 models in ads alone.
This is a huge potential win – especially when coupled with the likely metrics gains coming from more reactive models. After all, if we were able to get events to models 40 hours earlier, who knows how much better our ranking could get!
Future directions and conclusion
Like many hackathon projects, there’s no shortage of hurdles getting this work into a production state. Aside from the infrastructure required to actually architect a continuous-training pipeline, we’d need a significant number of high-quality checks and balances to ensure that updating models in real-time didn’t lead to sudden degradations in performance. The amount of development, number of parties involved, and the breadth of expertise to get this into production would surely be extensive. However, as ML continues to mature, we should be able to enable more complex architectures with less overhead.