In the past, sellers were responsible for managing and fulfilling their own tax obligations.
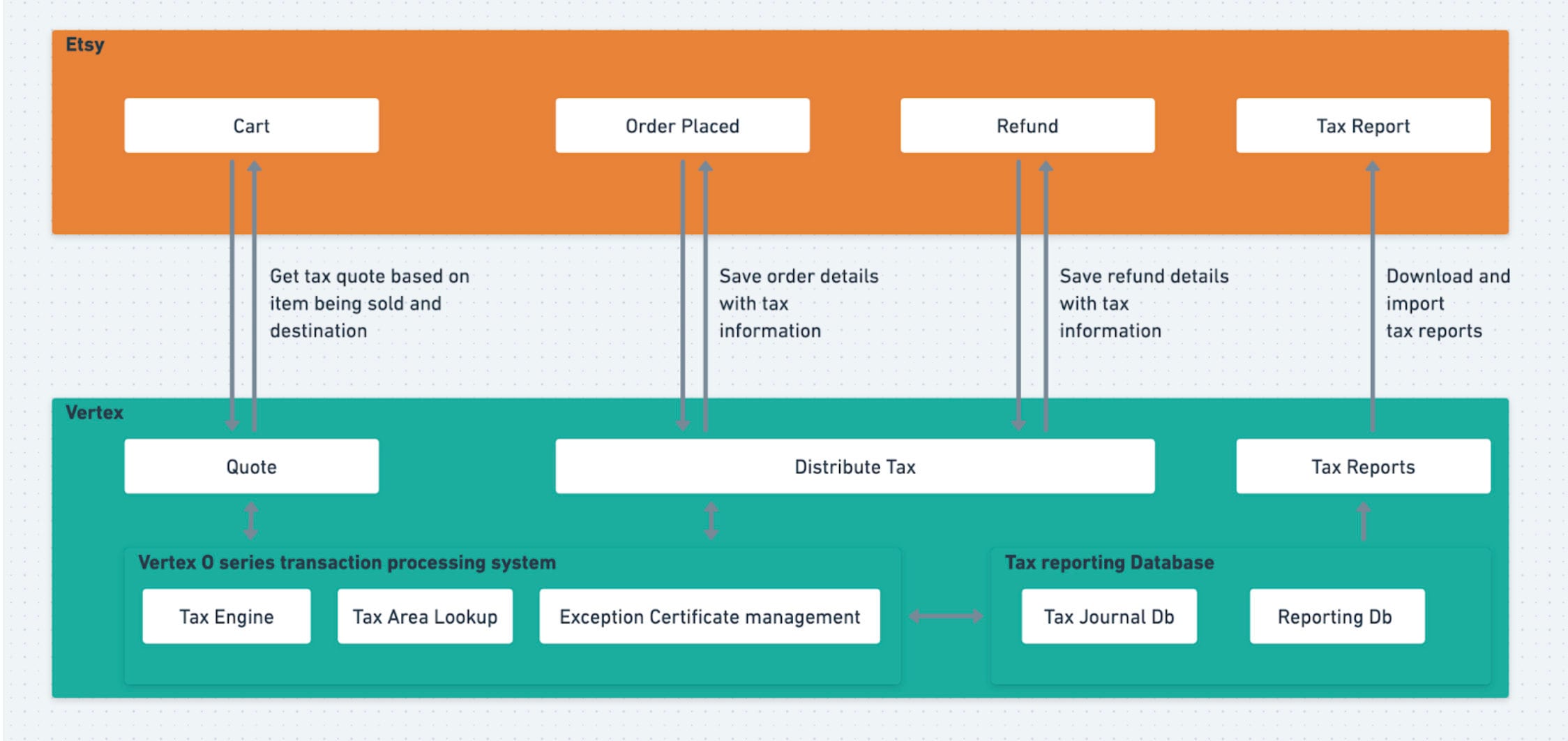
However, more and more jurisdictions are now requiring marketplaces such as Etsy to collect the tax from buyers and remit the tax to the relevant authorities. Etsy now plays an active role in collecting tax from buyers and remitting it all over the world. In this post, I will walk you through our tax calculation infrastructure and how we adapted to the ongoing increase in traffic and business needs over the years. The tax calculation workflow We determine tax whenever a buyer adds an item to their Etsy shopping cart. The tax determination is based on buyer and seller location and product category, and a set of tax rules and mappings. To handle the details of these calculations we partner with Vertex, and issue a call to their tax engine via the Quotation Request API to get the right amount to show in our buyer’s cart. Vertex ensures accurate and efficient tax management and continuously updates the tax rules and rates for jurisdictions around the world. The two main API calls we use are Quotation Request and DistributeTaxRequest SOAP calls. When the buyer proceeds to payment, an order is created, and we call back to Vertex with a DistributeTaxRequest sending the order information and tax details. We sync information with Vertex through the order fulfillment lifecycle. To keep things up to date in case an order is canceled or a refund needs to be issued later on, we inform the details of the cancellation and refunds to the tax engine via DistributeTaxRequest. This ensures that when Vertex generates tax reports for us they will be based on a complete record of all the relevant transactions.
Etsy collects the tax from the buyers and remits that tax to the taxing authority, when required. Generate tax details for reporting and audit purpose Vertex comes with a variety of report formats out of the box, and gives us tools to define our own. When Etsy calls the Distribute Tax API, Vertex saves the information we pass to it as raw metadata in its tax journal database. A daily cron job in Vertex then moves this data to the transaction detail table, populating it with tax info. When reports and audit data are generated, we download these reports and import to Etsy’s bigdata and the workflow completes. Mapping the Etsy taxonomy to tax categories Etsy maintains product categories to help our buyers find exactly the items they’re looking for. To determine whether transactions are taxed or exempt it’s not enough to know item prices and buyer locations: we have to map our product categories to Vertex’s rule drivers. That was an effort involving not just engineering but also our tax and analytics teams, and with the wide range of Etsy taxonomy categories it was no small task. Handling increased API traffic Coping with the continuous increase in traffic and maintaining the best checkout experience without delays has been a challenge all the time. Out of the different upgrades we did, the most important ones were to switch to multiple instances for vertex calls and shadowing. Multiple Instance upgrade In our initial integration, we were using the same vertex instance for Quotation and Distribute calls. And the same instance was responsible for generating the reports. This report generation started to affect our checkout experience. Reports are generally used by our tax team and they run them on a regular basis. But on top of that, we also run daily reports to feed the data captured by Vertex back into our own system for analytics purposes. We solved this by routing the quotation calls to one instance and then distributing them to the other. This helped in maintaining a clear separation of functionalities, and avoided interference between the two processes. We had to align the configurations between the instances as well.
Splitting up the quotation and distribution calls opened up the door to horizontal scaling, now we can add as many instances of each type and load balance the requests between instances. Eg: When a request type lists multiple instances, we load balance between the instances by using the cart_id for quotations and receipt_ids for distributes I.e. cart_id % quotation_instance_count Shadow logging Shadow logging the requests helped us to simulate the stress on Vertex and monitor the checkout experience. We used this technique multiple times in the past. Whenever we had situations like, for example, adding five hundred thousand more listings whose taxes would be passed through the Vertex engine, we were concerned that the increase in traffic might impact buyer experience. To ensure it wouldn’t, we tested for a period of time by slowly ramping shadow requests to Vertex: “Shadow requests” are test requests that we send to Vertex from orders, but without applying the calculated tax details to buyers’ carts. This will simulate the load on vertex and we can monitor the cart checkout experience. Once we have done shadowing and seen how well Vertex handled the increased traffic, we are confident that releasing the features ensures it would not have any performance implications. Conclusion

However, more and more jurisdictions are now requiring marketplaces such as Etsy to collect the tax from buyers and remit the tax to the relevant authorities. Etsy now plays an active role in collecting tax from buyers and remitting it all over the world. In this post, I will walk you through our tax calculation infrastructure and how we adapted to the ongoing increase in traffic and business needs over the years. The tax calculation workflow We determine tax whenever a buyer adds an item to their Etsy shopping cart. The tax determination is based on buyer and seller location and product category, and a set of tax rules and mappings. To handle the details of these calculations we partner with Vertex, and issue a call to their tax engine via the Quotation Request API to get the right amount to show in our buyer’s cart. Vertex ensures accurate and efficient tax management and continuously updates the tax rules and rates for jurisdictions around the world. The two main API calls we use are Quotation Request and DistributeTaxRequest SOAP calls. When the buyer proceeds to payment, an order is created, and we call back to Vertex with a DistributeTaxRequest sending the order information and tax details. We sync information with Vertex through the order fulfillment lifecycle. To keep things up to date in case an order is canceled or a refund needs to be issued later on, we inform the details of the cancellation and refunds to the tax engine via DistributeTaxRequest. This ensures that when Vertex generates tax reports for us they will be based on a complete record of all the relevant transactions.
Etsy collects the tax from the buyers and remits that tax to the taxing authority, when required. Generate tax details for reporting and audit purpose Vertex comes with a variety of report formats out of the box, and gives us tools to define our own. When Etsy calls the Distribute Tax API, Vertex saves the information we pass to it as raw metadata in its tax journal database. A daily cron job in Vertex then moves this data to the transaction detail table, populating it with tax info. When reports and audit data are generated, we download these reports and import to Etsy’s bigdata and the workflow completes. Mapping the Etsy taxonomy to tax categories Etsy maintains product categories to help our buyers find exactly the items they’re looking for. To determine whether transactions are taxed or exempt it’s not enough to know item prices and buyer locations: we have to map our product categories to Vertex’s rule drivers. That was an effort involving not just engineering but also our tax and analytics teams, and with the wide range of Etsy taxonomy categories it was no small task. Handling increased API traffic Coping with the continuous increase in traffic and maintaining the best checkout experience without delays has been a challenge all the time. Out of the different upgrades we did, the most important ones were to switch to multiple instances for vertex calls and shadowing. Multiple Instance upgrade In our initial integration, we were using the same vertex instance for Quotation and Distribute calls. And the same instance was responsible for generating the reports. This report generation started to affect our checkout experience. Reports are generally used by our tax team and they run them on a regular basis. But on top of that, we also run daily reports to feed the data captured by Vertex back into our own system for analytics purposes. We solved this by routing the quotation calls to one instance and then distributing them to the other. This helped in maintaining a clear separation of functionalities, and avoided interference between the two processes. We had to align the configurations between the instances as well.
Splitting up the quotation and distribution calls opened up the door to horizontal scaling, now we can add as many instances of each type and load balance the requests between instances. Eg: When a request type lists multiple instances, we load balance between the instances by using the cart_id for quotations and receipt_ids for distributes I.e. cart_id % quotation_instance_count Shadow logging Shadow logging the requests helped us to simulate the stress on Vertex and monitor the checkout experience. We used this technique multiple times in the past. Whenever we had situations like, for example, adding five hundred thousand more listings whose taxes would be passed through the Vertex engine, we were concerned that the increase in traffic might impact buyer experience. To ensure it wouldn’t, we tested for a period of time by slowly ramping shadow requests to Vertex: “Shadow requests” are test requests that we send to Vertex from orders, but without applying the calculated tax details to buyers’ carts. This will simulate the load on vertex and we can monitor the cart checkout experience. Once we have done shadowing and seen how well Vertex handled the increased traffic, we are confident that releasing the features ensures it would not have any performance implications. Conclusion
Given the volume of increasing traffic and the data involved, we will have to keep improving our design to support those. We’ve also had to address analytics, reporting, configuration sync and many more in designing the system, but we’ll leave that story for next time.